论文相似性检测工具 系统
基本原理:turnitin反剽窃软件自动将论文切割为多个50到200字(可自定义)的小文本,通过混合引擎将其与188亿个网页和490万篇文献进行模糊匹配,标示出每个文本块与文献库中的某些文献的最大相似度。由此软件统计出相似度≥95%(基本原封不动抄袭)与相似度≥80%(略作修改后抄袭)的字数所占总字数比例。我们把这个比例作为剽窃(相似)程度衡量指标。 系统需要XP系统,word2003环境。
论文相似性检测工具 优点
turnitin反剽窃软件覆盖面广,通过混合引擎覆盖约188亿个网页和490万篇论文。系统采用自研的ROST WebSpider和ROST SEAT算法实现了对互联网和部分期刊网的广度覆盖。 —— 模糊检测,柔性匹配,为防止抄袭者替换部分字符,删除部分标点符号,系统通过相似度来进行判定。系统采用自研的ROST Similar算法实现高速相似性检测和度量。系统采用自研的QingQing算法提取信息指纹,在P3、512MBPC上,分词速度为13MB/S,已在互联网提供评测版供业内评测。 本软件检测结果只能作为一个参考,可以使用表格右键导出详细检查结果发送给被检查本人,本软件不对是否剽窃做结论,只是告诉你与现存文献相似度高于80%的文字比例所占文章总数比例是多少。高于80%相似度的文字才是需要关注的。低于此值可以完全无视。 —— 规范引文及参考文献去除,降低误判可能性。 —— 自定义分块检测机制,将文章的每一文本块与其他论文的相似度都精确的表示出来了,每一文本块约为50字至200字不等(可自定义),以红色表示极度相似(相似度大于80%),一目了然,清晰醒目。当设为50个字一块时,可以在较低信息粒度上查找出可能抄袭或相似的文献。 —— 相似论文模块跟踪技术,可以通过简单操作直接定位相似论文中哪些内容被抄袭或者拷贝,直观明了。 —— 结果分析功能,自动分析论文相似结果,给出评价意见。 —— 多种文件格式支持,包括PDF、DOC、PPT、XLS、TXT等论文。 —— 专有数据文件保存,不用反复检测,浪费时间。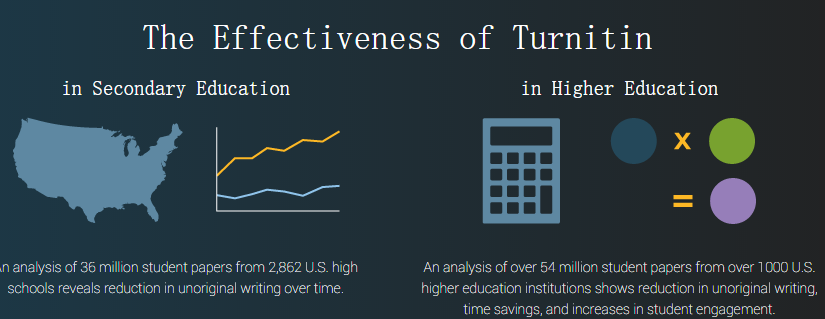
论文相似性检测工具 缺点
turnitin反剽窃软件不能覆盖世界上所有中英文文献,关于覆盖率与查全率的相关性问题,正在研究中。 —— 检测时间略长,本软件每检测200字需要7秒钟,一篇8000字的论文至少耗费约5分钟,需要一点点耐心。 —— 本软件检测结果存在一个小的误差,用更小的论文块进行检测,可以减少误差,但需要的时间会相应增加,经过我们在多家编辑部的试用情况,块数大小定为200字较为合适,此时误差率也是可以接受的,论文相似率一般是比实际的要低。 —— 在试用版中为了最大限度的检测出各类不同学科的最相关论文,本软件在某些情况下存在误判可能性,此时,用户可以通过调整设置中的两个参数来获得不同的相似指数结果。如果正式使用,请联系我们调整参数,将系统调整为较严格匹配,后面我们针对这一点会进行软件升级,并发行不同学科的版本
论文相似性检测工具 相关研究
1993年,Arizona大学的Manber提出近似指数概念用于度量文件之间字符串的相似性,这个思路被很多后来的相似系统所采用。1995年美国Stanford 大学的Brin 和Garcia-Molina在数字图书馆项目中提出COPS系统与相应算法,奠定了反剽窃系统的框架基础。香港理工大学的Si和Leong建立CHECK原型采用统计关键词的方法度量文本相似性,并且首次把论文结构信息引入文本相似性度量中。2000年Monostori 用后缀向量存储后缀树搜寻字符串之间的最大子串并建立了MDR原型。目前国外Turnitin公司提供的英文反剽窃服务遍及九十多个国家,检索网页数量超66亿,用户达650万,支持世界最大的四家电子教学平台BlackBoard、WebCT、Moodle、Angel。 开发者争取推出面向学生的免费在线防剽窃服务,防止无意识抄袭的发生。
论文相似性检测工具 面向社会的服务
turnitin反剽窃软件和其他系统覆盖文献有80%以上不同,本系统通过混合引擎覆盖188亿个网页以及490万篇论文,建议用户使用多套系统检测论文。 由于服务器压力,目前不对学生提供检测服务,对单位用户和高校教师开放免费测试,
词条标签:计算机学